前言
如何才能成功地处理、分析和理解数据:
- 获取数据(从各种数据源将数据导入程序);
- 整理数据(编码缺失值、修复或删除错误数据、将变量转换成更方便的格式);
- 注释数据(以记住每段数据的含义);
- 总结数据(通过描述性统计量了解数据的概况);
- 数据可视化(一图胜千言);
- 数据建模(解释数据间的关系,检验假设);
- 整理结果(创建具有出版水平的表格和图形)。
R简介
什么是R?
要是一本书里没有图画和对话,那还有什么意思呢?
——爱丽丝《爱丽丝梦游仙境》
R是一个非常灵活的平台,是专用于探索、展示和理解数据的语言,因此我引用了《爱丽丝梦游仙境》的句子来表示当今统计分析的潮流——一个探索、展示和理解的交互式过程。
R简史,前世今生
R语言是从S统计绘图语言演变而来,可看作S的“方言”。
S语言上世纪70年代诞生于贝尔实验室,是一种用来进行数据探索、统计分析和作图的解释型语言。
1995年由新西兰Auckland大学,基于S语言的源代码,编写了一能执行S语言的软件,并将该软件的源代码全部公开,这就是R软件,其命令统称为R语言。
R的特点
多领域的统计资源
目前在R网站上约有5000多个程序包,涵盖了基础统计学、社会学、经济学、生物信息等诸多反面。
跨平台
R可在多种操作系统下运行,如Windows、MacOS、Linux等。
命令行驱动
R即时解释,输入命令,即可获得相应结果。
为什么选择R?
丰富的资源
涵盖了多种行业数据分析中几乎所有方法。
良好的扩展性
十分方便的编写函数和程序包,跨平台,可以胜任复杂的数据分析、绘制精美的图形。
完备的帮助系统
每个函数都有统一格式的帮助,运行实例。
GNU软件
免费、软件本身及程序包的源代码公开
程序包
R程序包是多个函数的集合,具有详细的说明和示例。
Windows下的R包是经过编译的zip包。
每个程序包包含函数、数据、帮助文件、描述文件等。
R程序包是R功能扩展,特定的分析功能,需要用相应的程序包实现。
例如:画图常用到ggplot2程序包,系统发育分析,常用到ape程序包。
R语言数据类型与数据结构
R语言数据类型
| 类型 | ||
|---|---|---|
| Numeric(数字) | 12.3,5,999 | v <- 23.5 print(class(v)) :”numeric” |
| Integer(整型) | 2L,34L,0L | v <- 2L print(class(v)) :”integer” |
| Complex(复合型) | 3 + 2i | v <- 2+5i print(class(v)) : “complex” |
| Character(字符) | ‘a’ , ‘“good”, “TRUE”, ‘23.4’ | v <- “TRUE” print(class(v)) :”character” |
| Raw(原型) | “Hello” 被存储为 48 65 6c 6c 6f | v <- charToRaw(“Hello”) print(class(v : “raw” |
| Logical(逻辑型) | TRUE, FALSE | v <- TRUE print(class(v)) : “logical” |
R语言变量
变量为我们提供了我们的程序可以操作的命名存储。有效的变量名称由字母,数字和点或下划线字符组成。
变量名以字母或不以数字后跟的点开头。
| 变量名 | 合法性 | 原因 |
|---|---|---|
| var_name2. | 有效 | 有字母、数字、点和下划线 |
| VAR_NAME% | 无效 | 有字符% |
| 2var_name | 无效 | 数字开头 |
| .var_name, | 有效 | 可以用.开头 |
| .2var_name | 无效 | 用.开头,后面接数字 |
| _var_name | 无效 | 以_开头 |
R语言特殊运算符
| 符号 | 功能 | 例子 |
|---|---|---|
| %% | 两个向量求余 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v%%t) :2.0 2.5 2.0 |
| %/% | 两个向量相除求商 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v%/%t):0 1 1 |
| ^ | 将第二向量作为第一向量的指数 | v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v^t) :256.000 166.375 1296.000 |
| : | 冒号运算符。 它为向量按顺序创建一系列数字。 | v <- 2:8 print(v) :2 3 4 5 6 7 8 |
| %in% | 此运算符用于标识元素是否属于向量。 | TRUE FALSE |
R语言数据结构
向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c()可用来创建向量。各类向量如下例所示:
1
2
3a <- c(1,2,3)
b <- c("one","two","three")
c <- c(TRUE,TRUE,FALSE)通过在方括号中给定元素所处位置的数值,我们可以访问向量中的元素。例如,a[c(1,2)]用于访问向量a中的第1个和第2个元素。
1
2a[c(1,2)]
[1] 1 2
矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可通过函数matrix创建矩阵。

数组
数组(array)与矩阵类似,但是维度可以大于2。数组可通过array函数创建,形式如下:
1
myarray <-array(vector, dimensions, dimnames)
其中vector包含了数组中的数据,dimensions是一个数值型向量,给出了各个维度下标的最大值,而dimnames是可选的、各维度名称标签的列表。
示例:
1
2
3
4dim1 <- c("A1","A2")
dim2 <- c("B1","B2","B3")
dim3 <- c("C1","C2","C3","C4")
z <- array(1:24, c(2,3,4),dimnames = list(dim1,dim2,dim3))1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24从数组中选取元素的方式与矩阵相同。上例中,元素z[1,2,3]为15。
数据框
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。它与你通常在SAS、SPSS和Stata中看到的数据集类似。数据框将是你在R中最常处理的数据结构。
数据框可通过函数data.frame()创建:
1
mydata <-data.frame(col1, col2, col3,...)
其中的列向量col1, col2,col3,…可为任何类型(如字符型、数值型或逻辑型)。每一列的名称可由函数names指定。
1
2
3
4
5patientID <- c(1,2,3,4)
age <- c(25,34,28,52)
diabetes <- c("Type1","Type2","Type1","Type1")
status <- c("Poor","Improved","Excellent","Poor")
patientdata <- data.frame(patientID,age,diabetes,status)1
2
3
4
5
6> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poorattach()、detach()和with()
函数attach()可将数据框添加到R的搜索路径中。R在遇到一个变量名以后,将检查搜索路径中的数据框,以定位到这个变量。
函数detach()将数据框从搜索路径中移除。值得注意的是,detach()并不会对数据框本身做任何处理。
函数with(),大括号{}之间的语句都针对指定数据框执行
实例标识符
在病例数据中,病人编号(patientID)用于区分数据集中不同的个体。实例标识符(case identifier)可通过数据框操作函数中的rowname选项指定。
例如,语句:
1
patientdata <- data.frame(patientID, age, diabetes,status,row.names = patientID)
将patientID指定为R中标记各类打印输出和图形中实例名称所用的变量。
因子
变量可归结为名义型、有序型或连续型变量。名义型变量是没有顺序之分的类别变量。糖尿病类型Diabetes(Type1、Type2)是名义型变量的一例。有序型变量表示一种顺序关系,而非数量关系。病情Status(poor, improved, excellent)是顺序型变量的一个上佳示例。续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量。
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。
函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1… k ](其中k 是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
例子:
1
diabetes <- c("Type1","Type2","Type1","Type1")
语句diabetes <-factor(diabetes)将此向量存储为(1, 2, 1, 1),并在内部将其关联为1=Type1和2=Type2(具体赋值根据字母顺序而定)。针对向量diabetes进行的任何分析都会将其作为名义型变量对待。
列表
列表(list)是R的数据类型中最为复杂的一种。一般来说,列表就是一些对象(或成分,component)的有序集合。列表允许你整合若干(可能无关的)对象到单个对象名下。例如,某个列表中可能是若干向量、矩阵、数据框,甚至其他列表的组合。可以使用函数list()创建列表:
1
mylist <-list(object1, object2, ...)
其中的对象可以是目前为止讲到的任何结构。
1
2
3
4
5g <- "My First List"
h <- c(25,26,18,39)
j <- matrix(1:10,nrow = 5)
k <-c("noe","two","three")
mylist <- list(title = g, ages = h, j, k)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17> mylist
$title
[1] "My First List"
$ages
[1] 25 26 18 39
[[3]]
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
[[4]]
[1] "noe" "two" "three"注意:
- 对象名称中的句点(.)没有特殊意义。但美元符号
$却有着和其他语言中的句点类似的含义,即指定一个对象中的某些部分。例如,A$x是指数据框A中的变量x。 - R不提供多行注释或块注释功能。
- 将一个值赋给某个向量、矩阵、数组或列表中一个不存在的元素时,R将自动扩展这个数据结构以容纳新值。
- R中没有标量。标量以单元素向量的形式出现。
- R中的下标不从0开始,而从1开始。
- 变量无法被声明。它们在首次被赋值时生成。
- 对象名称中的句点(.)没有特殊意义。但美元符号
数据的输入
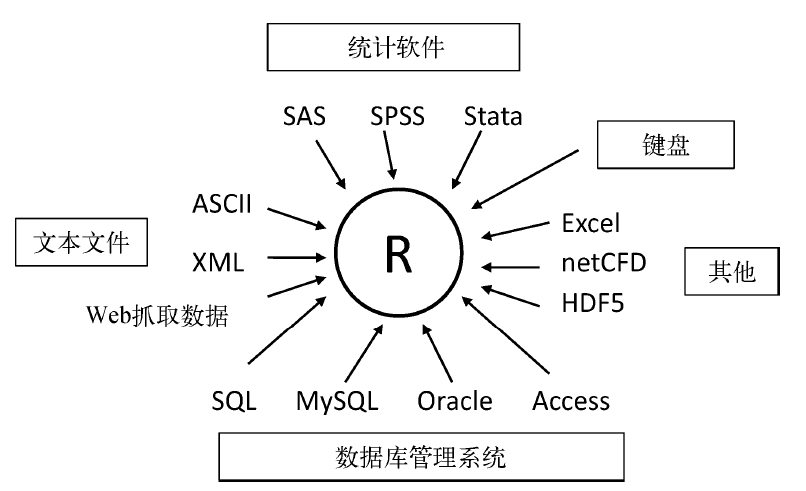
R可从键盘、文本文件、Microsoft Excel和Access、流行的统计软件、特殊格式的文件,以及多种关系型数据库中导入数据。
初阶绘图
通过执行如plot()、hist()(绘制直方图)或barplot()(创建条形图),可以很方便的绘制图形。
例子:
1 | H<- c(7,12,28,3,41) |
1 | n=50000; |
案例展示
《红楼梦》文本分析以及关系网络的挖掘。
在这里主要进行和挖掘了如下内容:
- 《红楼梦》数据的准备、预处理、分词等
- 《红楼梦》各个章节的字数、词数、段落等相关方面的关系
- 《红楼梦》整体词频和词云的展示
- 《红楼梦》各个章节的聚类分析并可视化,主要进行了根据IF-IDF的系统聚类和根据词频的LDA主题模型聚类
- 《红楼梦》中关系网络的探索,主要探索了各个章节的关系图和人物关系网路图
- 《红楼梦》数据的准备、预处理、分词等
1 | ## [1] "金荣" "人多势众" "贾瑞" "勒令" "秦钟" |
《红楼梦》各个章节的字数、词数、段落等相关方面的关系
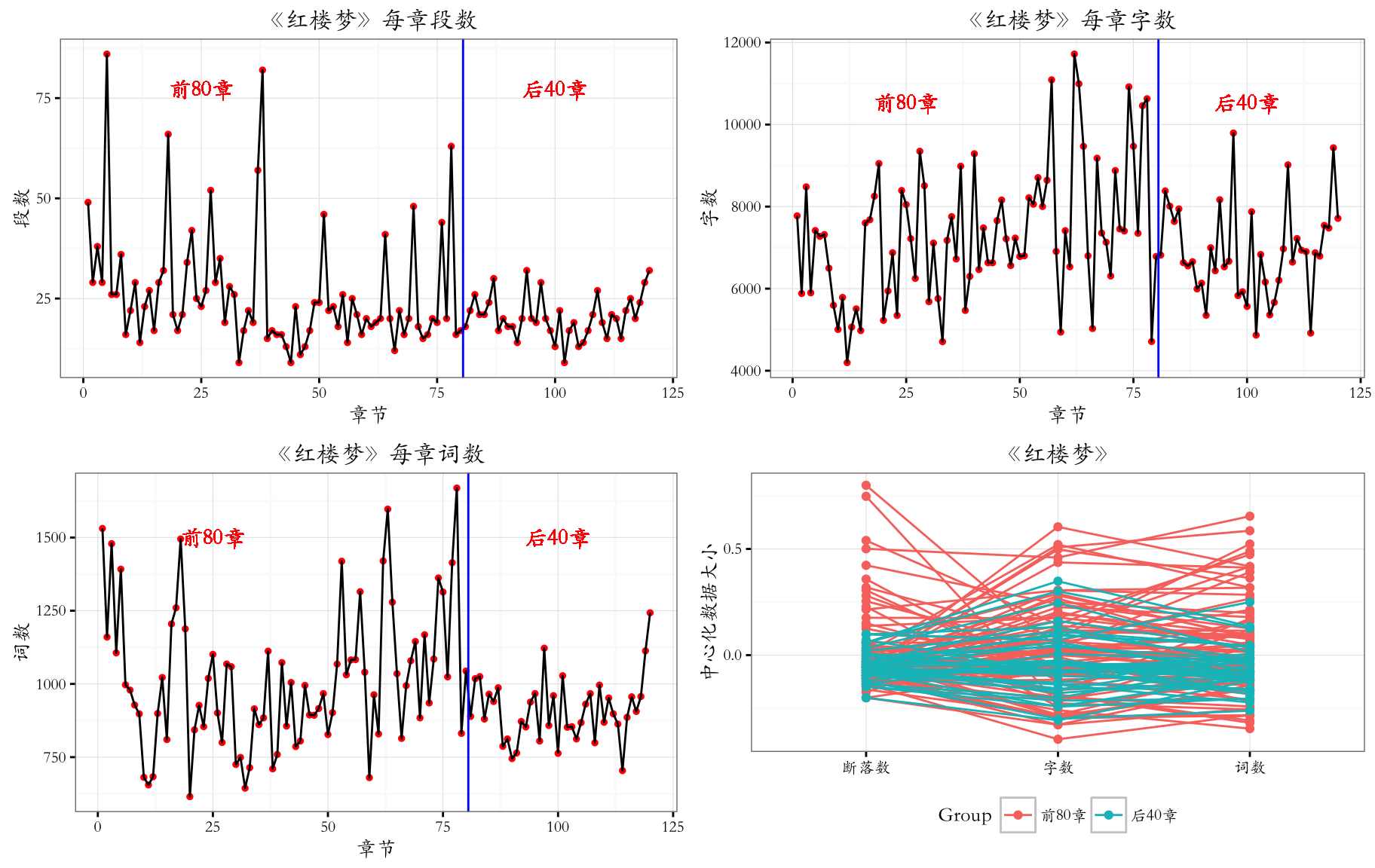
段落数、字数、词数三维散点图
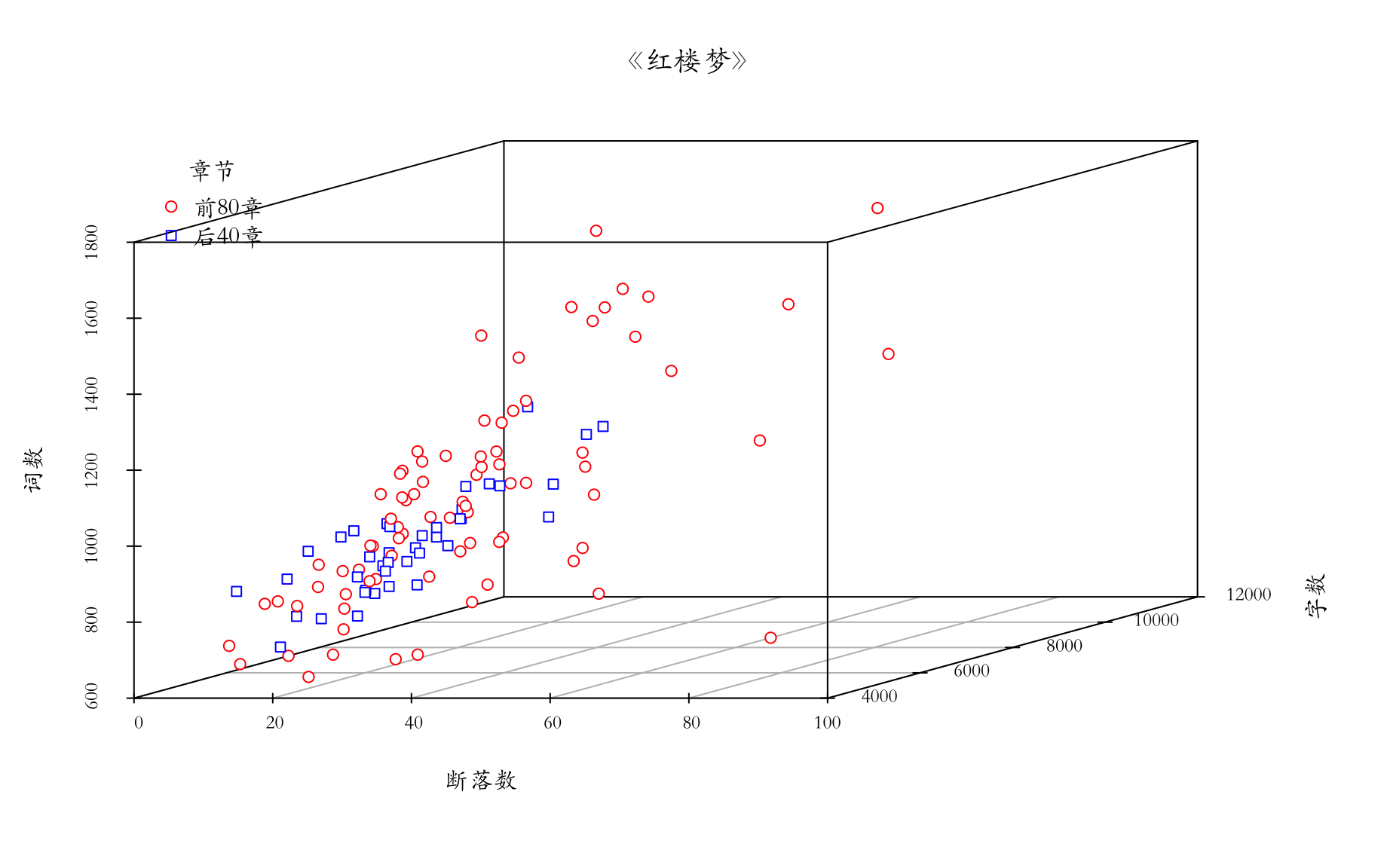
段落数、字数、词数矩阵散点图
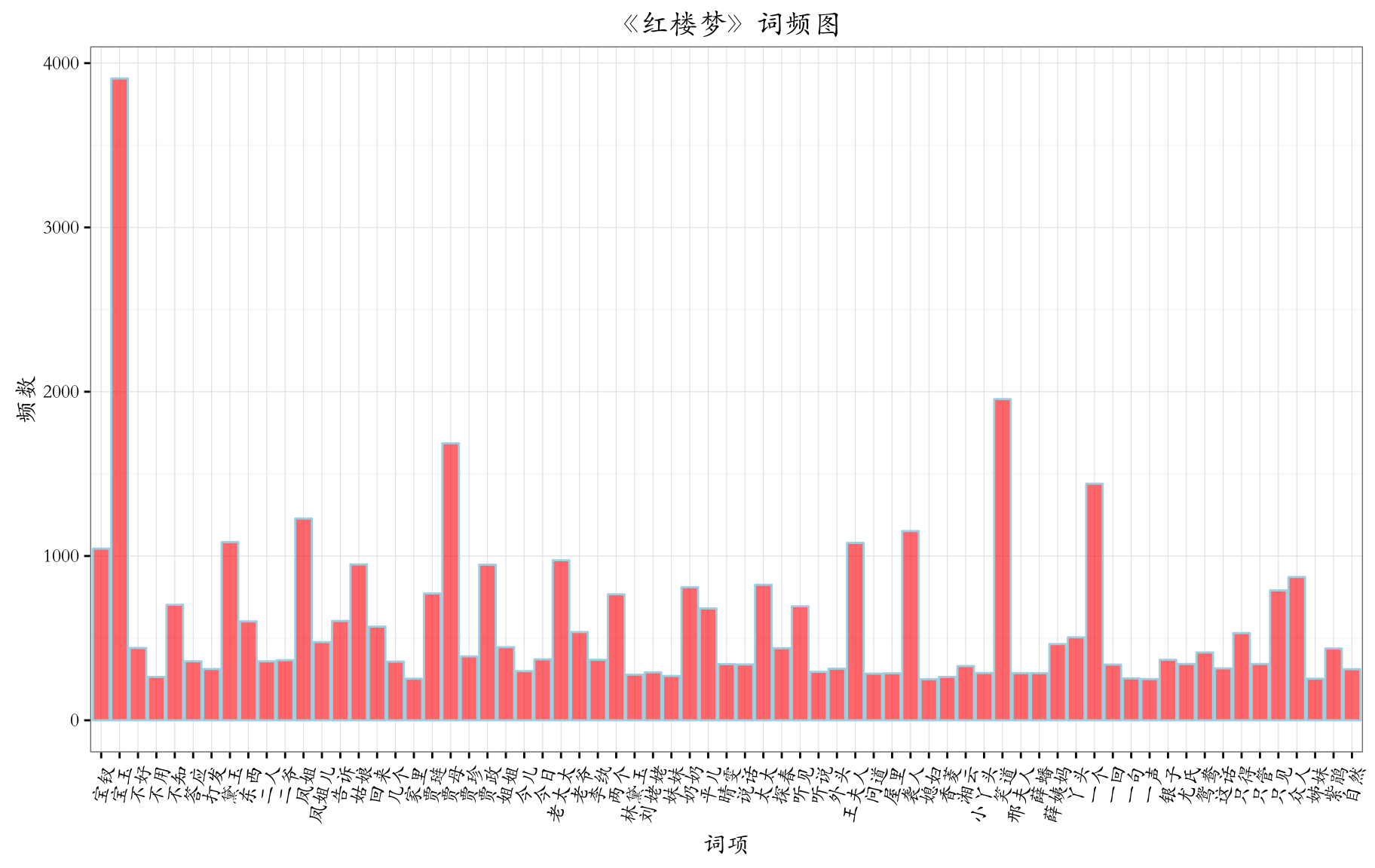
《红楼梦》整体词频和词云的展示

《红楼梦》中章节关系

源码实例
基础导入
1
2
3
4library(rJava)
library(Rwordseg)
library(RColorBrewer)
library(wordcloud)读入数据
1
lecture<-read.csv("E:/users/zeng/R/hongloumeng.txt", stringsAsFactors=FALSE,header=FALSE)
优化词库
1
2
3installDict("E:\\users\\zeng\\ciku\\红楼梦词汇大全.scel","hongloumeng1")
installDict("E:\\users\\zeng\\ciku\\红楼梦群成员名字词库.scel","hongloumeng2")
installDict("E:\\users\\zeng\\ciku\\红楼梦词汇.scel","hongloumeng3")分词+统计词频
1
2
3
4
5
6words=unlist(lapply(X=lecture, FUN=segmentCN))
#unlist将list类型的数据,转化为vector
#lapply()返回一个长度与X一致的列表,每个元素为FUN计算出的结果,且分别对应到X中的每个元素。
word=lapply(X=words, FUN=strsplit, " ")
v=table(unlist(word))
#table统计数据的频数完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34library(rJava)
library(Rwordseg)
library(RColorBrewer)
library(wordcloud)
#读入数据
lecture<-read.csv("E:/users/zeng/R/hongloumeng.txt", stringsAsFactors=FALSE,header=FALSE)
#文本预处理
res=lecture[]
#分词+频数统计
installDict("E:\\users\\zeng\\ciku\\红楼梦词汇大全.scel","hongloumeng1")
installDict("E:\\users\\zeng\\ciku\\红楼梦群成员名字词库.scel","hongloumeng2")
installDict("E:\\users\\zeng\\ciku\\红楼梦词汇.scel","hongloumeng3")
words=unlist(lapply(X=res, FUN=segmentCN))
#unlist将list类型的数据,转化为vector
#lapply()返回一个长度与X一致的列表,每个元素为FUN计算出的结果,且分别对应到X中的每个元素。
word=lapply(X=words, FUN=strsplit, " ")
v=table(unlist(word))
#table统计数据的频数
# 降序排序
v=rev(sort(v))
d=data.frame(词汇=names(v), 词频=v) #创建数据框
#过滤掉1个字和词频小于200的记录
d=subset(d, nchar(as.character(d$词汇))>1 & d$词频>=100)
#输出结果
write.csv(d, file="E:/users/zeng/hongloumongresult.csv", row.names=FALSE)
#画出标签云
mydata<-read.csv("E:/users/zeng/hongloumengresult.csv",head=TRUE)
mycolors <- brewer.pal(12,"Paired")
windowsFonts(myFont=windowsFont("锐字巅峰粗黑简1.0"))
wordcloud(mydata$词汇,mydata$词频,random.order=FALSE,random.color=TRUE,colors=mycolors,family="myFont")在黑板上写下50个数字:1至50.在接下来的49轮操作中,每次做如下动作:选取两个黑板上的数字a和b,擦去,在黑板上写|b – a|。请问最后一次动作之后剩下数字可能是什么?为什么?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17w=rep(0,7000)
for(j in 1:7000){
t=c(1:50)
for(i in 1:49){
q=sample(t,2)
a=q[1];b=q[2];c=abs(a-b)
t=t[-which(t==a)]
len1=length(t)-50+i
if(len1<0) t=c(t,rep(b,abs(len1)))
t=t[-which(t==b)]
len2=length(t)-49+i
if(len2<0) t=c(t,rep(b,abs(len2)))
t[length(t)+1]=c
if(length(t)==1) w[j]=t
}
}
summary(w)